本文主要记录学习1 Hello-Algo 的笔记。
复杂度分析
$$ \begin{aligned} O(1) < O(\log n) < O(n) < O(n \log n) < O(n^2) < O(2^n) < O(n!) \newline \text{常数阶} < \text{对数阶} < \text{线性阶} < \text{线性对数阶} < \text{平方阶} < \text{指数阶} < \text{阶乘阶} \end{aligned} $$
时间复杂度
空间复杂度
- 对象、变量、函数占用的内存空间
- 输出数据占用的空间
Q:递归的缺点有哪些?
A:递归函数每次调用自身时,系统都会为新开启的函数分配内存,以存储局部变量、调用地址和其他信息
- 函数的上下文数据都存储在称为“栈帧空间”的内存区域中,直至函数返回后才会被释放。因此,递归通常比迭代更加耗费内存空间
- 递归调用函数会产生额外的开销。因此递归通常比循环的时间效率更低
A:但是,尾递归会被编译器优化,效率与循环差不多
Q:递归有什么优点?
A:在使用分治法处理问题时,递归更直观。
迭代与递归特点对比
迭代 递归 实现方式 循环结构 函数调用自身 时间效率 效率通常较高,无函数调用开销 每次函数调用都会产生开销 内存使用 通常使用固定大小的内存空间 累积函数调用可能使用大量的栈帧空间 适用问题 适用于简单循环任务,代码直观、可读性好 适用于子问题分解,如树、图、分治、回溯等,代码结构简洁、清晰
数据结构
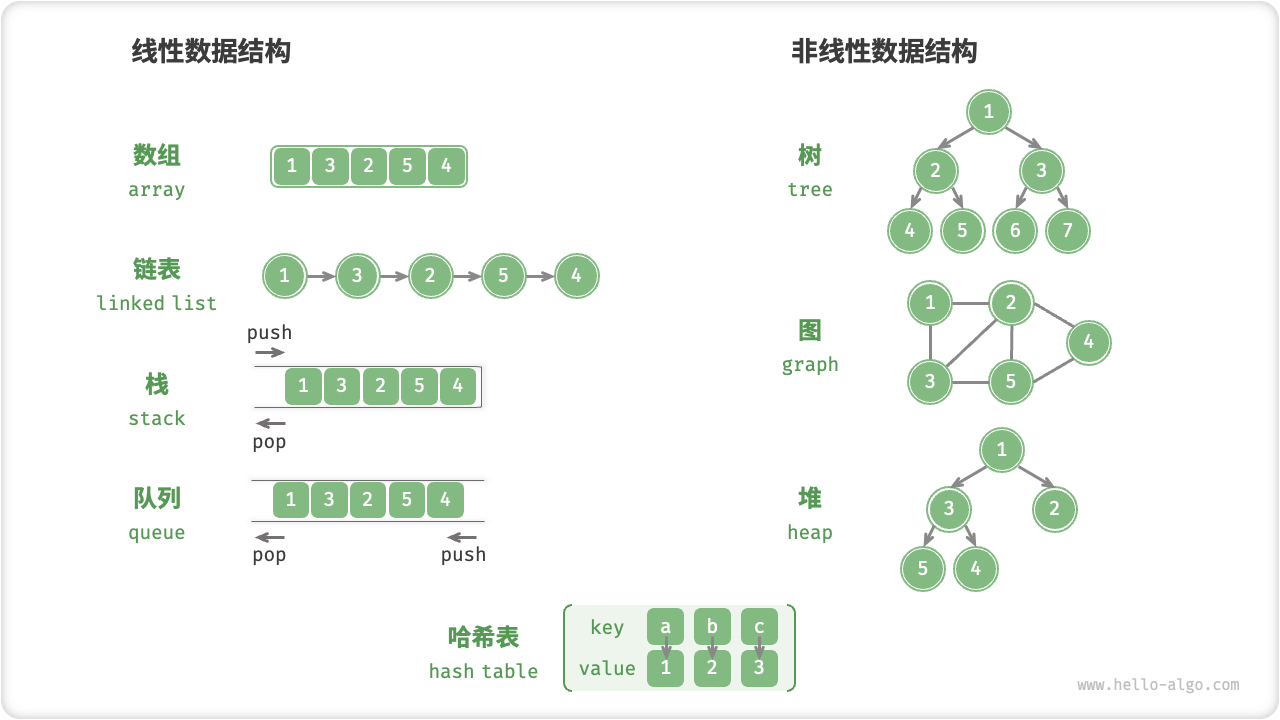
储存数组的空间是连续的,储存链表的空间是分散的。
数组的读取效率更高
获悉其中任意一个元素地址后,可以直接计算出其他任何元素的地址,有更少的寻址操作
对 CPU 缓存空间的利用
CPU 读取数据时,一次会读取 64 或 128 字节的数据到缓存中,数组在内存中是连续的,所以,后面的命中更可能是在缓存中,缓存中的数据读取效率更高
链表的插入效率更高
数组插入需要调整后面所有数据的位置,而链表只需要修改当前位置和上一位置数据的指针
基本数据类型
整数
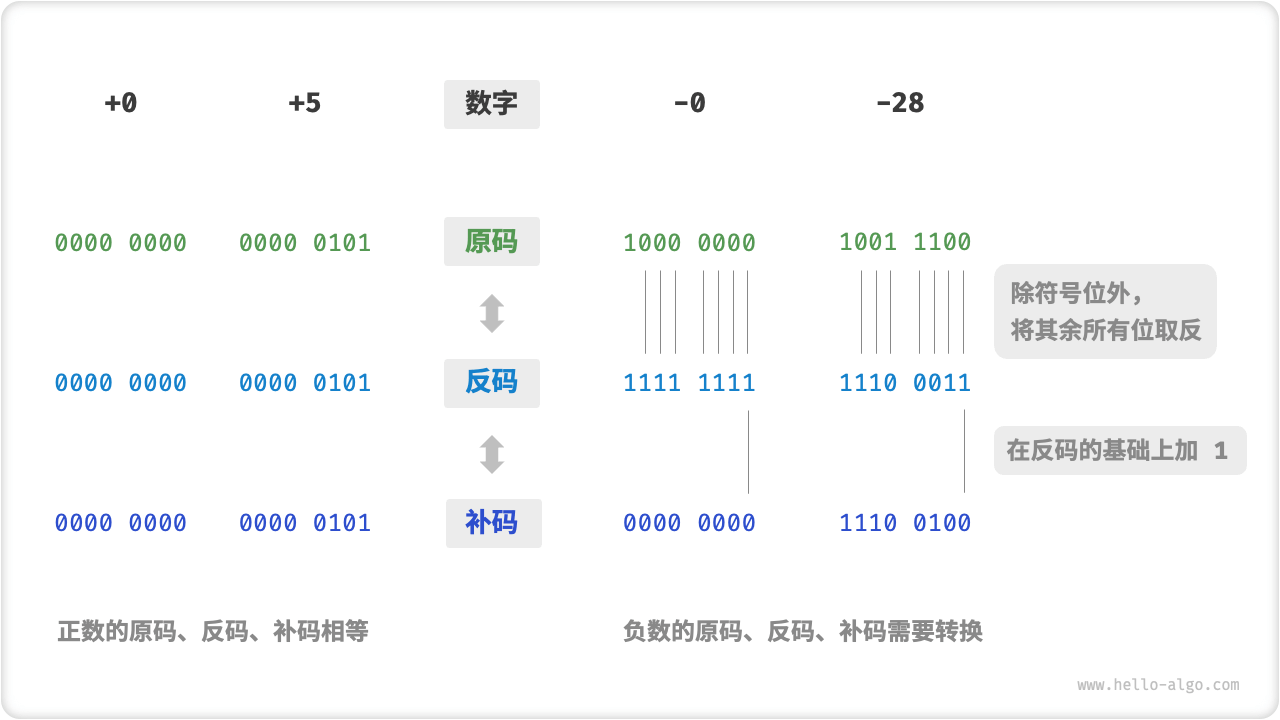
计算机硬件电路基于加法实现,更简单且效率更高。但是,针对整数的正负数相加,原码相加的结果不正确,所以制定了反码。但是反码的0和-0相加结果不正确,如果单独判断,有较大的性能损失,所以制定了补码进行加法运算。
Float 和 Double
符号位、指数位、尾数位
|
|
Float
共4字节,32位。
符号位1个,指数位8个,尾数位23个

Double
共8字节,64位。
符号位1个,指数位16个,尾数位47个
数组与链表
数组:是一种线性数据结构,其将相同类型元素存储在连续的内存空间中。
链表:是一种线性数据结构,其中的每个元素都是一个节点对象,各个节点通过“引用”相连接。
- 数组和链表是两种基本的数据结构,分别代表数据在计算机内存中的两种存储方式:连续空间存储和分散空间存储。两者的特点呈现出互补的特性。
- 数组支持随机访问、占用内存较少;但插入和删除元素效率低,且初始化后长度不可变。
- 链表通过更改引用(指针)实现高效的节点插入与删除,且可以灵活调整长度;但节点访问效率低、占用内存较多。
- 常见的链表类型包括单向链表、循环链表、双向链表,它们分别具有各自的应用场景。
- 列表是一种支持增删查改的元素有序集合,通常基于动态数组实现,其保留了数组的优势,同时可以灵活调整长度。
- 列表的出现大幅地提高了数组的实用性,但可能导致部分内存空间浪费。
- 程序运行时,数据主要存储在内存中。数组提供更高的内存空间效率,而链表则在内存使用上更加灵活。
- 缓存通过缓存行、预取机制以及空间和时间局部性等数据加载机制,为 CPU 提供快速数据访问,显著提升程序的执行效率。
- 由于数组具有更高的缓存命中率,因此它通常比链表更高效。在选择数据结构时,应根据具体需求和场景做出恰当选择。
栈与队列
栈:遵循先入后出的逻辑的线性数据结构。
队列:遵循先入先出规则的线性数据结构。
- 栈是一种遵循先入后出原则的数据结构,可通过数组或链表来实现。
- 从时间效率角度看,栈的数组实现具有较高的平均效率,但在扩容过程中,单次入栈操作的时间复杂度会劣化至 O(n) 。相比之下,基于链表实现的栈具有更为稳定的效率表现。
- 在空间效率方面,栈的数组实现可能导致一定程度的空间浪费。但需要注意的是,链表节点所占用的内存空间比数组元素更大。
- 队列是一种遵循先入先出原则的数据结构,同样可以通过数组或链表来实现。在时间效率和空间效率的对比上,队列的结论与前述栈的结论相似。
- 双向队列是一种具有更高自由度的队列,它允许在两端进行元素的添加和删除操作。
哈希表
哈希表,又称为散列表,通过建立键 key 与值 value 之间的映射,实现高效的元素查询。可以用数组或者链表实现。
- 输入
key,哈希表能够在 O(1) 时间内查询到value,效率非常高。- 常见的哈希表操作包括查询、添加键值对、删除键值对和遍历哈希表等。
- 哈希函数将
key映射为数组索引,从而访问对应桶并获取value。- 两个不同的
key可能在经过哈希函数后得到相同的数组索引,导致查询结果出错,这种现象被称为哈希冲突。- 哈希表容量越大,哈希冲突的概率就越低。因此可以通过扩容哈希表来缓解哈希冲突。与数组扩容类似,哈希表扩容操作的开销很大。
- 负载因子定义为哈希表中元素数量除以桶数量,反映了哈希冲突的严重程度,常用作触发哈希表扩容的条件。
- 链式地址通过将单个元素转化为链表,将所有冲突元素存储在同一个链表中。然而,链表过长会降低查询效率,可以进一步将链表转换为红黑树来提高效率。
- 开放寻址通过多次探测来处理哈希冲突。线性探测使用固定步长,缺点是不能删除元素,且容易产生聚集。多次哈希使用多个哈希函数进行探测,相较线性探测更不易产生聚集,但多个哈希函数增加了计算量。
- 不同编程语言采取了不同的哈希表实现。例如,Java 的
HashMap使用链式地址,而 Python 的Dict采用开放寻址。- 在哈希表中,我们希望哈希算法具有确定性、高效率和均匀分布的特点。在密码学中,哈希算法还应该具备抗碰撞性和雪崩效应。
- 哈希算法通常采用大质数作为模数,以最大化地保证哈希值的均匀分布,减少哈希冲突。
- 常见的哈希算法包括 MD5、SHA-1、SHA-2 和 SHA3 等。MD5 常用于校验文件完整性,SHA-2 常用于安全应用与协议。
- 编程语言通常会为数据类型提供内置哈希算法,用于计算哈希表中的桶索引。通常情况下,只有不可变对象是可哈希的。
树
二叉树(binary tree):一种非线性数据结构,代表着祖先与后代之间的派生关系,体现着“一分为二”的分治逻辑
- 二叉树是一种非线性数据结构,体现“一分为二”的分治逻辑。每个二叉树节点包含一个值以及两个指针,分别指向其左子节点和右子节点。
- 对于二叉树中的某个节点,其左(右)子节点及其以下形成的树被称为该节点的左(右)子树。
- 二叉树的相关术语包括根节点、叶节点、层、度、边、高度和深度等。
- 二叉树的初始化、节点插入和节点删除操作与链表操作方法类似。
- 常见的二叉树类型有完美二叉树、完全二叉树、完满二叉树和平衡二叉树。完美二叉树是最理想的状态,而链表是退化后的最差状态。
- 二叉树可以用数组表示,方法是将节点值和空位按层序遍历顺序排列,并根据父节点与子节点之间的索引映射关系来实现指针。
- 二叉树的层序遍历是一种广度优先搜索方法,它体现了“一圈一圈向外”的分层遍历方式,通常通过队列来实现。
- 前序、中序、后序遍历皆属于深度优先搜索,它们体现了“走到尽头,再回头继续”的回溯遍历方式,通常使用递归来实现。
- 二叉搜索树是一种高效的元素查找数据结构,其查找、插入和删除操作的时间复杂度均为 �(log�) 。当二叉搜索树退化为链表时,各项时间复杂度会劣化至 �(�) 。
- AVL 树,也称为平衡二叉搜索树,它通过旋转操作,确保在不断插入和删除节点后,树仍然保持平衡。
- AVL 树的旋转操作包括右旋、左旋、先右旋再左旋、先左旋再右旋。在插入或删除节点后,AVL 树会从底向顶执行旋转操作,使树重新恢复平衡。
堆
堆:一种满足特定条件的完全二叉树,分为小顶堆和大顶堆。
- 堆是一棵完全二叉树,根据成立条件可分为大顶堆和小顶堆。大(小)顶堆的堆顶元素是最大(小)的。
- 优先队列的定义是具有出队优先级的队列,通常使用堆来实现。
- 堆的常用操作及其对应的时间复杂度包括:元素入堆 O(log(n))、堆顶元素出堆 O(log(n) 和访问堆顶元素 �(1) 等。
- 完全二叉树非常适合用数组表示,因此我们通常使用数组来存储堆。
- 堆化操作用于维护堆的性质,在入堆和出堆操作中都会用到。
- 输入 n 个元素并建堆的时间复杂度可以优化至 O(n) ,非常高效。
- Top-K 是一个经典算法问题,可以使用堆数据结构高效解决,时间复杂度为 O(n * log(n)) 。
图
略
搜索
二分查找
「二分查找 binary search」是一种基于分治策略的高效搜索算法。它利用数据的有序性,每轮减少一半搜索范围,直至找到目标元素或搜索区间为空为止。
时间复杂度:O(log(n))
空间复杂度:o(1)
|
|
二分查找优点:
- 效率高
- 省空间
二分查找的局限性:
- 二分查找仅适用于有序数据。若输入数据无序,为了使用二分查找而专门进行排序,得不偿失。因为排序算法的时间复杂度通常为 O(n * log(n)) ,比线性查找和二分查找都更高。对于频繁插入元素的场景,为保持数组有序性,需要将元素插入到特定位置,时间复杂度为 O(n) ,也是非常昂贵的。
- 二分查找仅适用于数组。二分查找需要跳跃式(非连续地)访问元素,而在链表中执行跳跃式访问的效率较低,因此不适合应用在链表或基于链表实现的数据结构。
- 小数据量下,线性查找性能更佳。在线性查找中,每轮只需要 1 次判断操作;而在二分查找中,需要 1 次加法、1 次除法、1 ~ 3 次判断操作、1 次加法(减法),共 4 ~ 6 个单元操作;因此,当数据量 n 较小时,线性查找反而比二分查找更快。
哈希查找
- 适合对查询性能要求很高的场景,平均时间复杂度为 �(1) 。
- 不适合需要有序数据或范围查找的场景,因为哈希表无法维护数据的有序性。
- 对哈希函数和哈希冲突处理策略的依赖性较高,具有较大的性能劣化风险。
- 不适合数据量过大的情况,因为哈希表需要额外空间来最大程度地减少冲突,从而提供良好的查询性能。
树查找
- 适用于海量数据,因为树节点在内存中是分散存储的。
- 适合需要维护有序数据或范围查找的场景。
- 在持续增删节点的过程中,二叉搜索树可能产生倾斜,时间复杂度劣化至 �(�) 。
- 若使用 AVL 树或红黑树,则各项操作可在 �(log�) 效率下稳定运行,但维护树平衡的操作会增加额外开销。
排序算法
选择排序
|
|
冒泡排序
|
|
插入排序
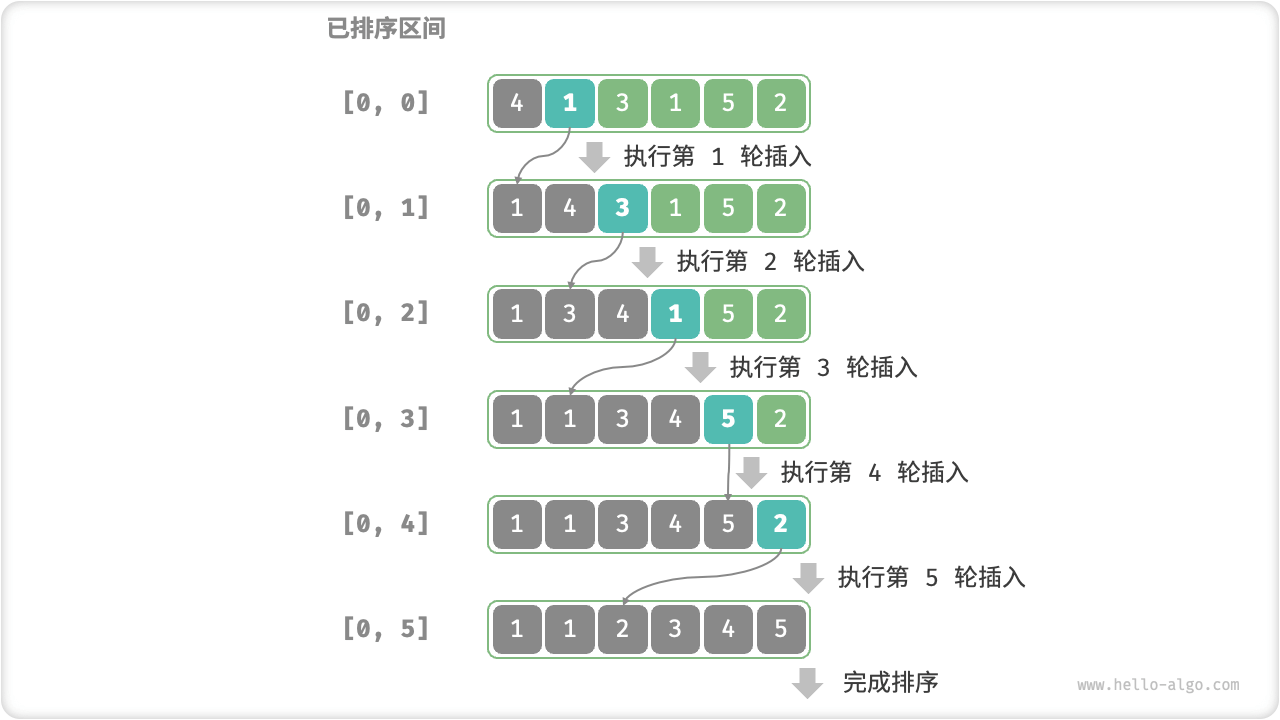
|
|